How to get image url from html string using regex
Description
<img\b(?=\s)(?=(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*?\ssrc=['"]([^"]*)['"]?)(?:[^>=]|='[^']*'|="[^"]*"|=[^'"\s]*)*"\s?\/?>
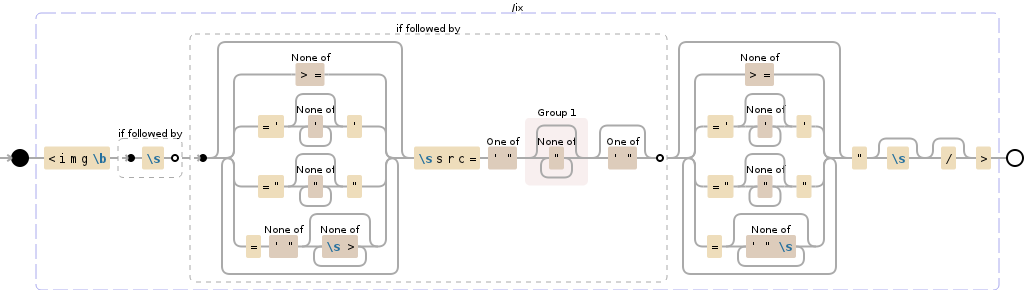
This regular expression will do the following:
- This regex captures the entire IMG tag
- Places the source attribute value into capture group 1, without quotes if they exist.
- Allow attributes to have single, double or no quotes
- Can be modified to validate any number of other attributes
- Avoid difficult edge cases which tend to make parsing HTML difficult
Example
Live Demo
https://regex101.com/r/qW9nG8/1
Sample text
Note the difficult edge case in the first line where we are looking for a specific droid.
<img onmouseover=' if ( 6 > 3 { funSwap(" src="NotTheDroidYourLookingFor.jpg", 6 > 3 ) } ; ' src="http://website/ThisIsTheDroidYourLookingFor.jpeg" onload="img_onload(this);" onerror="img_onerror(this);" data-pid="jihgfedcba" data-imagesize="ppew" />
some text
<img src="http://website/someurl.jpeg" onload="img_onload(this);" />
more text
<img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
Sample Matches
- Capture group 0 gets the entire IMG tag
- Capture group 1 gets just the src attribute value
[0][0] = <img onmouseover=' funSwap(" src='NotTheDroidYourLookingFor.jpg", data-pid) ; ' src="http://website/ThisIsTheDroidYourLookingFor.jpeg" onload="img_onload(this);" onerror="img_onerror(this);" data-pid="jihgfedcba" data-imagesize="ppew" />
[0][1] = http://website/ThisIsTheDroidYourLookingFor.jpeg
[1][0] = <img src="http://website/someurl.jpeg" onload="img_onload(this);" />
[1][1] = http://website/someurl.jpeg
[2][0] = <img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
[2][1] = https://en.wikipedia.org/wiki/File:BH_LMC.png
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
<img '<img'
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the least amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)*? end of grouping
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
src= 'src='
----------------------------------------------------------------------
['"] any character of: ''', '"'
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
['"]? any character of: ''', '"' (optional
(matching the most amount possible))
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"\s]* any character except: ''', '"',
whitespace (\n, \r, \t, \f, and " ") (0
or more times (matching the most amount
possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
\/? '/' (optional (matching the most amount
possible))
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
This is the regex pattern you should use:
(http[^\s]+(jpg|jpeg|png|tiff)\b)
Translation:
- Find everything that starts with "http"
- No white spaces allowed
- Ends with one of the following jpg, jpeg, png, tiff
Regex function:
func matches(for regex: String!, in text: String!) -> [String] {
do {
let regex = try RegularExpression(pattern: regex, options: [])
let nsString = text as NSString
let results = regex.matches(in: text, range: NSMakeRange(0, nsString.length))
return results.map { nsString.substring(with: $0.range)}
} catch let error as NSError {
print("invalid regex: \(error.localizedDescription)")
return []
}
}
Usage:
var matched = matches(for: "(http[^\\s]+(jpg|jpeg|png|tiff)\\b)", in: String(htmlStr))
Note:
- matched returns as an array with matching string objects
- This code was written for Swift 3
Just a slight tweak to the pattern give me this:
let string = "some text and other text <img src=\"en.wikipedia.org/wiki/File:BH_LMC.png\"/>;and then more text and more text"
let matches = string.regex("<img[^>]+src*=\".*?\"['/']>")
returns an array with the match.