Passing an object with circular references from server to client-side Javascript while retaining circularity
Douglas Crockford has a solution for this that I have successfully used to solve this problem before: Cycle.js
instead of just using stringify and parse you would first call decycle and restore with retrocycle
var jsonString = JSON.stringify(JSON.decycle(parent));
var restoredObject = JSON.retrocycle(JSON.parse(jsonString));
JSFiddle
I recommend my siberia package, which is up on on github
First, I'll explain the algorithm via example. Here is our example data structure (Joe likes apples and oranges, while Jane likes apples and pears.)
var Joe = { name: 'Joe' };
var Jane = { name: 'Jane' };
var Apple = { name: 'Apple' };
var Orange = { name: 'Orange' };
var Pear = { name: 'Pear' };
function addlike(person, fruit){
person.likes = person.likes || [];
fruit.likedBy = fruit.likedBy || [];
person.likes.push(fruit);
fruit.likedBy.push(person);
}
addlike(Joe, Apple); addlike(Joe, Orange);
addlike(Jane, Apple); addlike(Jane, Pear);
var myData = { people: [Joe, Jane], fruits: [Apple, Orange, Pear] };
This gives us the following object graph (the root object, myData, is the tree with the crown, center left)
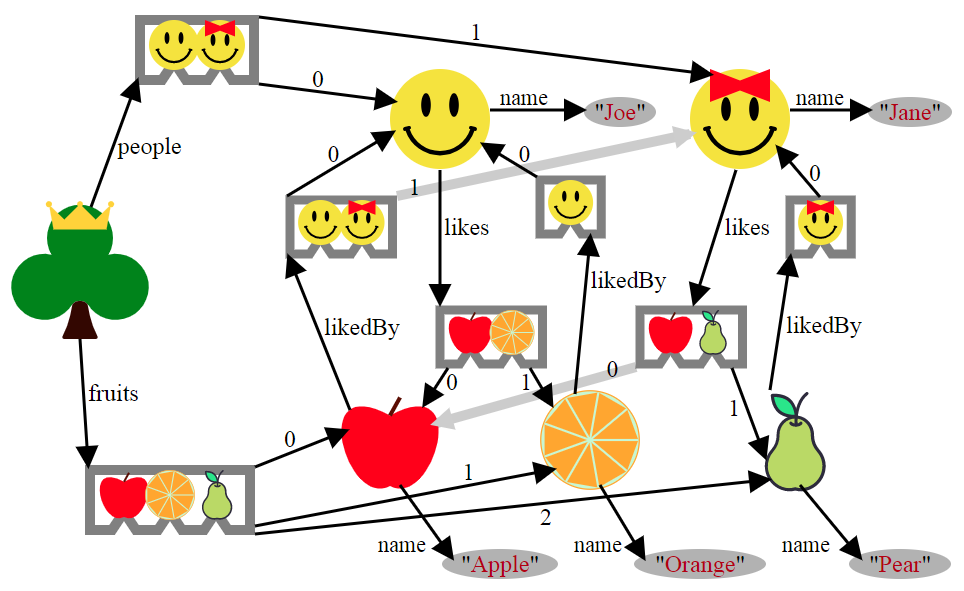
To serialize, we have to find a way of encoding the information contained in our object graph in a non-cyclical fashion.
When we determine the object graph by applying the a recusive discover function to the root object (discover is essentially depth first search with an added stop condition for already seen objects), we can easily "count" the nodes (objects) of the object graph, i.e., label them with consecutive integers, starting at zero (zero always being the label for the root). We'll then also "count" the encountered non-objects (or "atoms"); they'll get the negative integers as labels. In our example, all atoms are strings. [A more general example would contain other atom types - such as numbers and "quasi-atomic objects", e.g. regular expressions or date objects (JavaScript builtin objects having a standard way of stringifying them)]. For example, the pear gets number 8 simply because it's the 8th object discovered by our search algorithm. Here is the object graph again with those integer labels added.
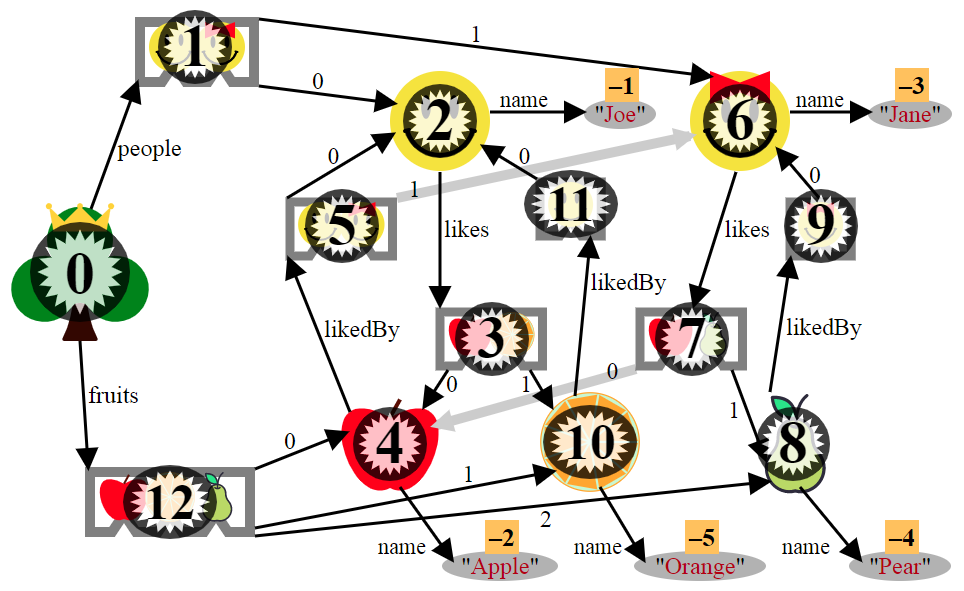
With the integer labels, serializing is easy. The "frozen version" of each object is an object with the same keys, but each of the values replaced by some integer. Each of these integers is an index into some table; either the objects table, or, in case the of a negative number, the atoms table.
Here is the objects table of our example.
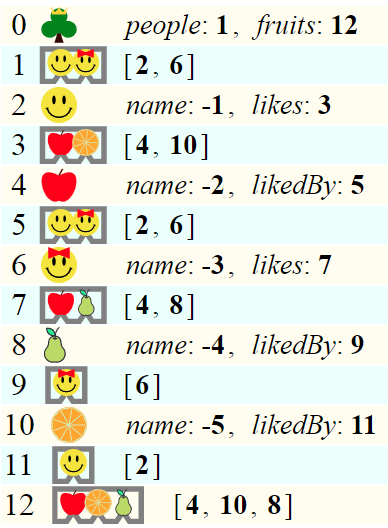
And the atoms table

For example, the frozen version of the pear object (which has .name = "Pear" and .likedBy = array containing Jane) is the object {name: -4, likedBy: 9}, because the atoms table has string "Pear" in slot 4, and the objects table has an array containing Jane in slot 9.
A slightly simplified version of the serialization algorithm (namely, one which does everything except deal with typing the atoms; especially, it will work for our example data structure) has only 32 lines of code, here it is:
function forestify_aka_decycle(root){
var objects = [], inverseObjects = new WeakMap(), forest = [];
var atomics = {}, atomicCounter = 0;
function discover(obj){
var currentIdx = objects.length;
inverseObjects.set(obj, currentIdx);
objects.push(obj);
forest[currentIdx] = Array.isArray(obj) ? [] : {};
Object.keys(obj).forEach(function(key){
var val = obj[key], type = typeof val;
if ((type==='object')&&(val!==null)){
if (inverseObjects.has(val)){ // known object already has index
forest[currentIdx][key] = inverseObjects.get(val);
} else { // unknown object, must recurse
forest[currentIdx][key] = discover(val);
}
} else {
if (!(val in atomics)){
++atomicCounter; // atoms table new entry
atomics[val] = atomicCounter;
}
forest[currentIdx][key] = -atomics[val]; // rhs negative
}
});
return currentIdx;
}
discover(root);
return {
objectsTable: forest,
atomsTable : [null].concat(Object.keys(atomics))
};
}
The objects table, being an array which in each slot contains a simple key-value pair list (with is a depth 1 tree), is called the forest, thus the name. And since the trees of the forest are frozen, "siberia" was chosen as the name of the algorithm.
The reverse process (unforestify aka retrocycle) in even more straightforward: First, for each tree in the forest, generate either an empty array, or an empty plain object. Then, in a double loop over trees of the forest, and keys of the tree, do an obvious assignment, the right hand side of which is a "thawed" tree in the thawed forest we're just constructing, or a atom fetched from the atmoics table.
function thawForest(forestified) {
var thawedObjects = [];
var objectsTable = forestified.objectsTable;
var atomsTable = forestified.atomsTable;
var i, entry, thawed, keys, j, key, frozVal;
for (i=0; i<objectsTable.length; i++){
entry = objectsTable[i];
thawedObjects[i] = Array.isArray(entry) ? [] : {};
}
for (i=0; i<objectsTable.length; i++){
entry = objectsTable[i];
thawed = thawedObjects[i];
keys = Object.keys(entry);
for (j=0; j<keys.length; j++){
key = keys[j];
frozVal = entry[key];
thawed[key] = (frozVal>=0) ? thawedObjects[frozVal] : atomsTable[-frozVal];
}
}
return thawedObjects;
};
function unforestify(forestified){ return thawForest(forestified)[0]; }
Above simplified versions of forestify and unforestify you can find in file siberiaUntyped.js (below 100 lines of code), which is not used, but provided for easier learning. Main differences between the simplified version and the real version are, first, atom typing, and second, the real version has non-recursive version of forsetify (little hard to read, admittedly), in order to prevent a stack overflow error you otherwise would get when you're dealing with extremely large objects (such as linked list with 100,000 nodes.)
Douglas Crockford
Why siberia is faster than Douglas Crockford's decycle.js (2018 version), by an unbounded factor: First, a similarity. Above discover function is similar to the function derez, which occurs inside of .decycle. Just as discover, derez is essentially depth first search with an additional stop condition if a previously encountered object is encountered once again, and in both cases, ES6 feature WeakMap is used to generate a lookup table of known objects. In both cases, the domain of the WeakMap consists of the nodes of the object graph (i.e., objects discovered so far.) But those objects are mapped to different things in discover vs derez. In discover, it's the object index, and in derez it's the path from the root to the object. That path is JavaScript code, which is later fed to eval, when we deserialize again.
For example, we already saw that our pear object is mapped (by discover) to the number 8, because it's the 8th object being discovered. Let's look at above depiction of the object graph, and trace the path from root to pear, i.e. 0 -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8. We encounter objects root -> AllPeople -> Joe -> JoesFruits -> Apple -> AppleEaters -> Jane -> JanesFruits -> Pear. The keys (edge labels) we see between those objects are "people", 0, "likes", 0, "likedBy", 1, "likes", 1.

Now, in the Douglas Crockford version, we can do
dougsFridge = JSON.decycle(myData)
dougsFridge.fruits[2].$ref
The result will be following string:
$["people"][0]["likes"][0]["likedBy"][1]["likes"][1]
It is not surprising at all that of the many possible paths from root to pear, siberia and Douglas Crockfords algorithm found the same route. After all, both are depth first search with "seen already" stop condition added, garnished with storing some stuff.
The difference: Storing the the path takes up space which is linear in the number of nodes involved, which is unbounded, and in the other direction, from path to thawed object, that then has runtime which is linear in the number of nodes involved. On the other hand, in siberia, storing the information of the path takes constant space (just one integer is stored), and going back from that integer to the thawed object is just an array lookup, which takes constant time.
On top of that, eval and regular expressions are used, which can be slow (especially the latter), further degrading runtime performance. (This being by far not as bad as the other problem.)
here is a speed test page showing comparing siberia and Douglas Crockfords cycle.js