When to Denormalize a Database Design
1) This is an archive. Everything that is in it should never be updated. I'd go with the senior guy's suggestion and have that invoice table be self-contained. Perhaps use a blob for the invoice itself that contains markup language?
2) Reporting services, a warehouse table that is trigger-updated, something you build by script whenever... these would all be fine, I think. It is indeed ideal to be normalized, but it isn't always fast. I have a good sized healthcare database I manage which is fully normalized... and then has a series of de-normalized tables with rolled-up equations and commonly pulled fields. Almost everything runs from that de-normalized set -- it's just faster to append to these with a trigger when files are loaded than to keep having to pull from various tables everytime I want to look at a 100,000 record report.
You raise valid points, however you are not completely clear on normalization and what it means, for example in
1) The claim that keeping the invoices as they were denormalizes the data is completely and totally wrong.
Let's take price for example - if you have a business requirement that states that you have to keep history of prices then keeping only current price is wrong and it breaks the requirements. And it has nothing to do with normalization, it's simply not designed well. Denormalization is about introducing possibilities for ambiguity into your model (and other artifacts) - and in this case you are simply not modelling your problem space properly.
There is nothing wrong in modelling your database to support temporal data (or versioning and/or separating the areas of the database into archive/temporal and the working set).
Looking at normalization without looking at semantics (in terms of requirements) is not possible.
Also, if your senior developer can't see the difference then I guess he didn't get his seniority in RDBMS development ;)
2) Second part is indeed denormalization. However, if you ever run across senior DB analyst who seriously preaches normalization, you will hear him/her say that it is perfectly acceptable to denormalize as long as you do it consciously and ensure that benefits overweight deficiencies and that anomalies will not bite you. They will also tell you to normalize the logical model and that in the physical model you are allowed to deviate from the ideal for various purposes (performance, maintenance, etc...). In my book the main purpose of normalisation is so that you don't have hidden anomalies (see this article on 5NF for example)
The caching of intermediate results is allowed even on normalized databases and even by biggest evangelists of normalization - you can do it at application layer (as some sort of cache) or you can do it at the database level or you can have a data warehouse for such purposes. These are all valid choices and have nothing to do with normalizing the logical model.
Also, as for your accountant - you should be able to convince him that what he is claiming is not a good test and develop a set of tests (maybe together with him) that will automate the testing of the system without users intervention and give you higher confidence that your system is bug free.
On the other hand I know of systems that require users to enter duplicate information, such as to enter the number of lines on the invoice before or after entering actual lines, to insure that the entry is complete. This data is 'duplicated' and you don't have to store it if you have a procedure that will validate the input. If that procedure comes later it is allowed to store the 'denormalized' data - again, the semantics justify it and you can look at the model as normalized. (it is beneficial to wrap your head around this concept)
EDIT: The term "denormalized" in (2) is not correct if you look at the formal definition of normal forms and if you consider a design denormalized if it breaks any of the normal forms (to some people this is obvious and there is no other way about it).
Still, you might want to get used to the idea that a lot of people and not necessary useless texts will use the term normalization for any effort that tries to reduce redundancy in the database (just as an example, you will find scientific papers, by which I don't say that they must be right, just as a warning that it is common, that call derived attributes a form of denormalization, see here).
If you want to refer to some more coherent and recognized authorities (again, not recognized by all), maybe the words of C.J.Date can make a clear distinction:
Much of design theory has to do with reducing redundancy; normalization reduces redundancy within relvars, orthogonality reduces it across relvars.
qouted from Database in depth: relational theory for practitioners
and on the next page
just as a failure to normalize all the way implies redundancy and can lead to certain anomalies, so too can a failure to adhere to orthogonality.
So, the proper term for redundancy across relvars is orthogonality (basically all normal forms talk about single relvar so if you look strictly at normalization it would never suggest any improvements due to dependencies between two different relvars).
Anyway, one of the other important concepts when you consider database design is also a difference between logical and physical database models. A lot of things that are useful on physical level, such as tables with subtotals or indexes have no place in the logical model - where you try to establish and investigate relationships between the concepts you are trying to model. And that's why you can say they are permissible and they don't ruin the design.
Lines sometimes can be a bit blurry on what is logical model and what is physical model. Especially good example is a table with subtotals. To consider it part of physical implementation and ignore it on the logical level you have to:
- ensure that users (and applications) can not update the subtotal table directly in a manner that is not consistent with their predicate (in another words have a bug in the subtotalling procedure)
- ensure that users (and applications) can not update the table on which these are dependent without updating the subtotal (in another words that some application will not delete a row from the detail table without updating the total)
If you break any of the above rules you will end up with inconsistent database which will provide inconsistent facts. (In such case if you want to formally design a procedure for fixing or examining the problems caused, you would not consider it just an additional table, it would exist at the logical level; where it should not be).
Also, the normalisation always depends on the semantics and the business rules you are trying to model. For example DBAPerformance gives an example in which storing the TaxAmount in the transaction table is not denormalized design, but he fails to mention that it depends what kind of system you are trying to model (is that obvious?); for example if the transaction has another attribute called TaxRate it will usually be denormalized because there is functional dependency on a set of non-key attributes (TaxAmount = Amount * TaxRate => FD: Amount,TaxRate -> TaxAmount), and one of these should be removed or guaranteed to be consistent.
Obviously, you might say, but, if the system you are building is for an audit company, then you might not have functional dependency - they might be auditing someone who is using manual calculations or has faulty software or must have ability to record incomplete data and the calculation might be wrong originally and as audit company you must record the fact as it happened.
So, semantics (predicates) which are determined by requirements will influence if any of the normal forms are broken - by influencing functional dependencies (in another words correctly establishing functional dependencies is quite important part of modelling when you strive for normalized database).
I agree with your senior about (1). A transaction table row must capture the entire state at the moment of the transaction. Period. What you're suggesting doesn't record the actual data, so it's inadmissible. I also agree about (2). Whatever the business wants by way of crosschecking, you must implement. Accounting is based on cross checking, double entry, rolling up ledgers, etc. You must do it. This so fundamental that you shouldn't even look on it as denormalization, just as implementing the business requirement.
Your senior colleague is a developer, not a data modeller. You are better off starting from scratch, without them. Normalisation is complicated only to those who will not read books. It is fair enough that he makes you think, but some of the issues are absurd.
Your numbers:
You need to appreciate the differences between actual online data, and historic data; then the difference between merely historic and archival needs. All of them are right for the specific business requirement, and wrong for all others, there is no universal right and wrong.
- why is there no paper-based copy of the invoice ? In most countries that would be a legal and tax requirement, what exactly is the difficulty of fishing out the old invoice ?
- where the database has the requirement of storing the closed invoices, then sure, as soon as the invoice is closed, you need a method of capturing that information.
ProductPrice(actually, I would call itProductDate) is a good idea, but may not be necessary. But you are right, you need to evaluate the currency of data, in the full context of the whole database.- I cannot see how copying the product price to the invoice table would help (are not there many line items ?)
- in modern databases, where the copy of the invoice is required to be regurgitated, the closed Invoice is additionally stored in a different form, eg XML. One customer saves the PDFs as BLOBs. So there is no messing around with what the product price was five years ago. But the basic invoice data is online and current, even for closed invoices; you just cannot recalculate ancient invoice using current prices.
- some people use an archive_invoice table, but that has problems because now every code segment or user report tool has to look in two places (note that these days some users understand databases better than most developers)
- Anyway, that is all discussion, for your understanding. Now for the technical intent.
- The database serves current and archival purposes from the one set of tables (no "archive" tables
- Once an Invoice is created, it is a legal document, and cannot be changed or deleted (it can be reversed or partially credited by a new Invoice, with negative values). They are marked
IsIssued/IsPaid/Etc Productscannot be deleted, they can be markedIsObsolete- There are separate tables for InvoiceHeader and InvoiceItem
InvoiceItemhas FKs to bothInvoiceHeaderandProduct- for many reasons (not only those you mention), the InvoiceItem row contains the
NumUnits; ProductPrice; TaxAmount; ExtendedPrice. Sure, this looks like a "denormalisation" but it is not, because prices, taxation rates, etc, are subject to change. But more important, the legal requirement is that we can reproduce the old invoice on demand. - (where it can be reproduced from paper files, this is not required)
- the
InvoiceTotalAmountis a derived column, justSUM()of the InvoiceItems
That is rubbish. Accounting systems, and accountants do not "work" like that.
If it is a true accounting system, then it will have JournalEntries, or "double entry"; that is what a qualified account is required to use (by law).
Double Entry Accounting does not mean duplicate entries; it means every financial transaction (one amount) shall have a source account and target account that it is applied to; so there is no "denormalisation" or duplication. In a banking database, because the financial transactions are against single accounts, that is commonly rendered as two separate financial transactions (rows) within one Db Transaction. Ordinary commercial database constraints are used to ensure that there are two "sides" to every financial transaction.
Ensuring that Invoices are not deleteable is a separate issue, to do with security, etc. if anyone is paranoid about things being deleted from their database, and their database was not secured by a qualified person, then they have more and different problems that have nothing to do with this question. Obtain a security audit, and do whatever they tell you.
Wikipedia is not a reliable source of information about any technical subject, let alone Normalisation.
A Normalised database is always much faster than Un-Normalised database
So it is very important to understand what Normalisation and Denormalisaion is, and what it isn't. The process is greatly hindered when people have fluid and amateur "definitions", it just leads to confusion and time-wasting "discussions". When you have fixed definitions, you can avoid all that, and just get on with the job.Summary tables are quite normal, to save the time and processing power, of recalculating info that does not change, eg: YTD totals for every year but this year; MTD totals for every month in this year but not this month. "Always recalculating" data is a bit silly when (a) the info is very large and (b) does not change. Calculate for the current month only
- In banking systems (millions of Trades per day), at EndOfDay, we calculate and store Daily Total as well. These are overwritten for the last five days, because Auditors are making changes, and JournalEntries against financial transactions for the last 5 days are allowed.
- non-banking systems generally do not need daily totals
Summary tables are not a "denormalisation" (except in the eyes of those who have just learned about "normalisation" from their magical, ever-changing fluid "source"; or as non-practitioners, who apply simple black-or-white rules to everything). Again, the definition is not being argued here; it simply does not apply to Summary tables.
Summary tables do not affect data integrity (assuming of course that the data that they were sourced from was integral).
Summary tables are an addition to the current data, which are not required to have the same constraints as the current data. There are essentially reporting tables or data warehouse tables, as opposed to current data tables.
There are no Update Anomalies (which is a strict definition) related to Summary tables. You cannot change or delete an invoice from last year. Update Anomalies apply to true Denormalised or Un-Normalised current data.
Response to Comments
so its ok to do denormalisation for the sakes of archiving right?
My explanation above appears not to be clear enough. Let's look at an example, and compare the options.

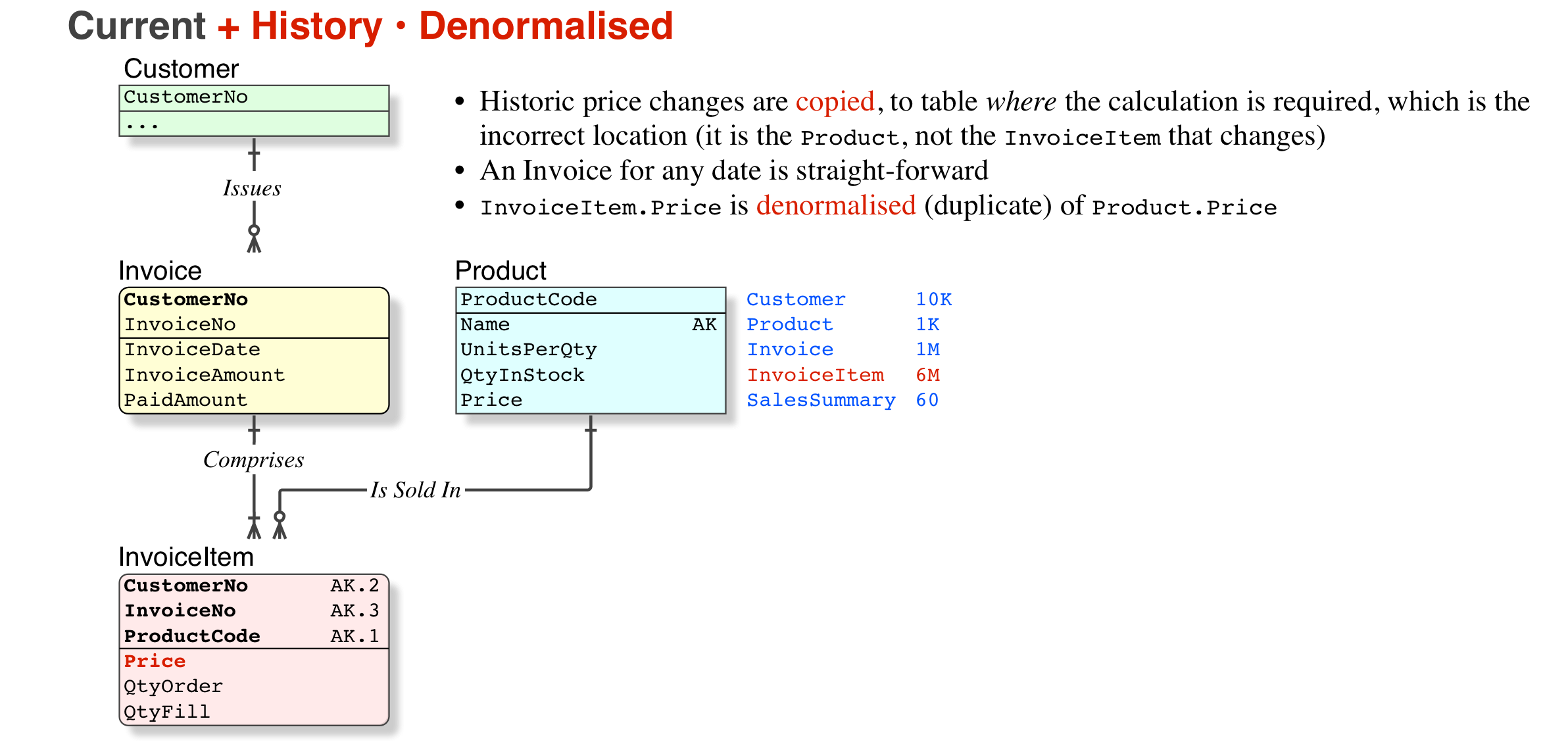
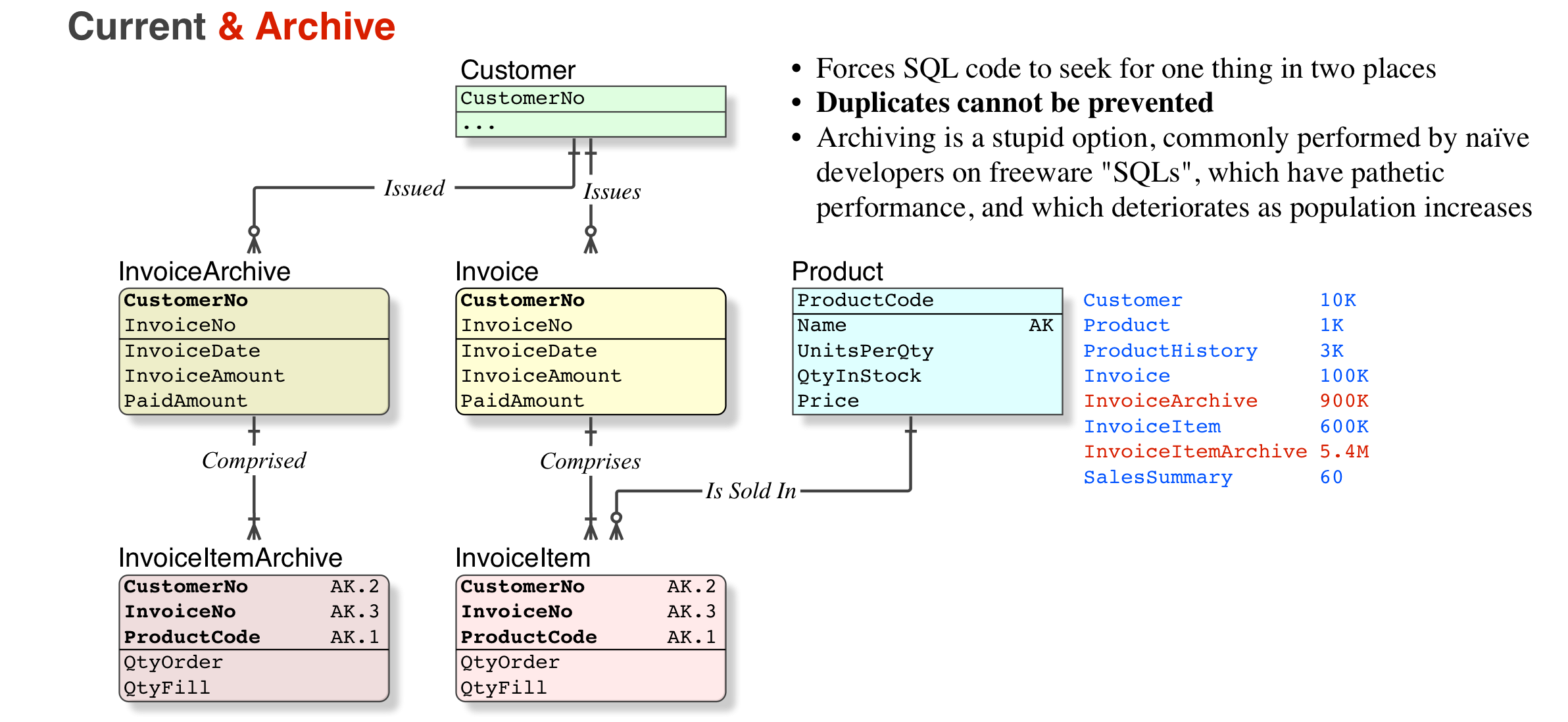
So, no. Archiving is a hideous option (I have corrected thousands of archived tables back to their home; corrected the indices, and restored normal performance, as well as returning the SELECT to query just one table instead of two). But if you do archive, it is not denormalised, it is worse, a copy.
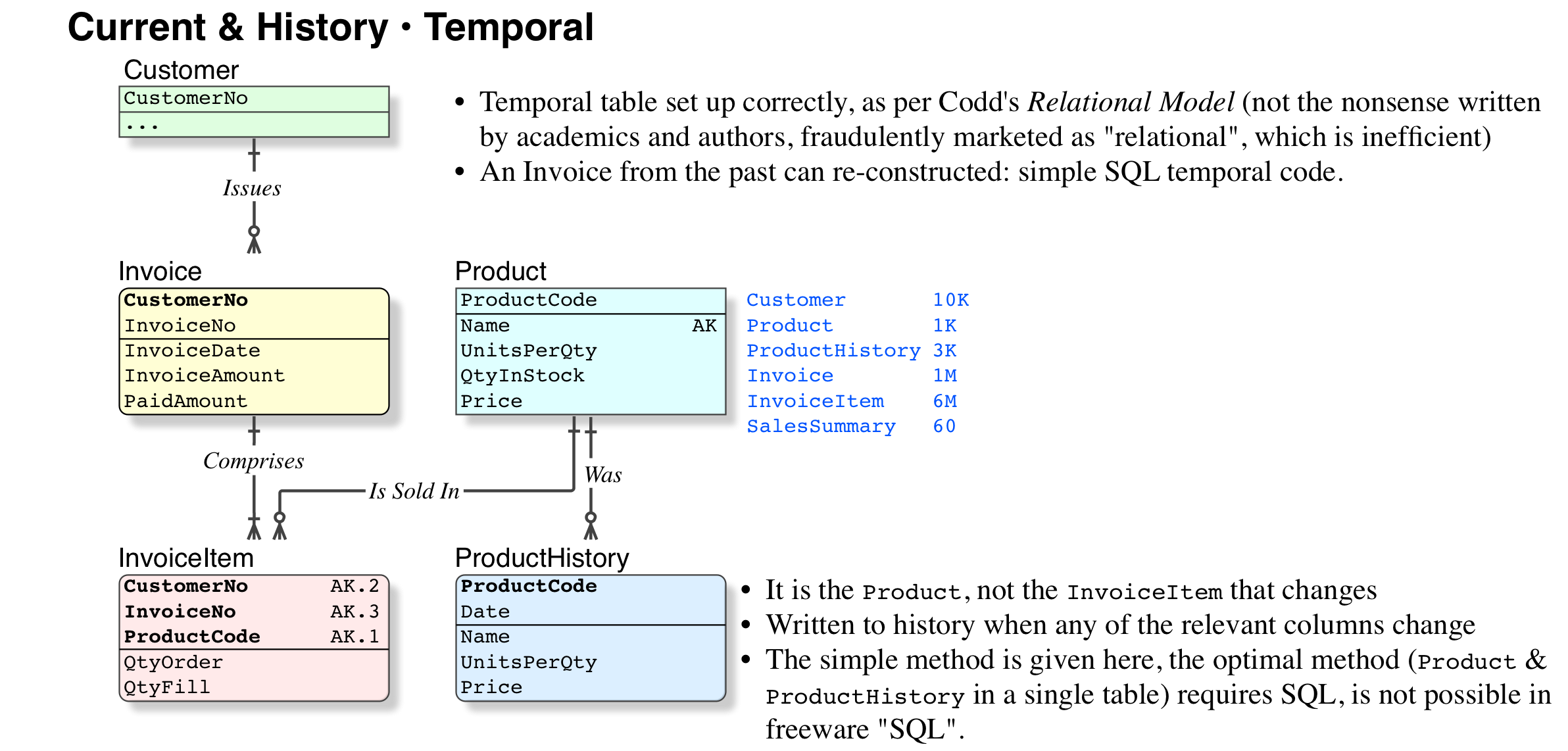
The best option by far. Again, this is the simple version, the full version requires an understanding of the temporal definition in Codd's Relational Model (not the ever-changing nonsense marketed by the detractors), and an SQL-compliant platform.
I disagree strongly with the statement that "A Normalised database is always much faster than Unnormalised database". That is patently false even if I don't harp on the use of "always". There are many scenarios in which selective, coherent denormalization of a database can result in extreme performance improvement.
Example [of justified De-Normalisation]: a complex join for a date-limited data set, like a month-end summary for a complex business. If the data is collected over the course of a month; then forever stable; and queried often — it can make sense to pre-compute via a materialized view, trigger, or more sophisticated method.
Evidently we need clear definitions.
Normalisation
- Purpose
to eliminate (not merely reduce) duplicate data
Note that there are no complex joins, just ordinary simple joins. - Method
Formal Relational data modelling
(not stepping through the NFs by number).
- Purpose
Un-Normalised
Failure to Normalise properly, leaving Update Anomalies in the database, and makes a mess of the TransactionsDe-Normalised
After formal Normalisation, one or more columns additionally placed in chosen tables, for performance reasons.- Eg. the pretend "SQL" does not perform the normal query with acceptable speed.
- Note that, over a period of 40 years of replacing poor databases, all databases that were declared to be De-normalised have in fact been Un-Normalised.
Summary Table/Materialised View
As detailed above in the Answer (please read again), and as illustrated in the graphic Current Only, it is an additional table to serve the purpose of providing summary values for history, that does not change. This is common.- There is no column that is duplicated, it cannot be categorised as "De-Normalisation".
You were not in disagreement with my statement [A Normalised database is always much faster than Unnormalised database], which relates to Normalised vs Un-Normalised, you were categorising the summary table incorrectly, as "de-Normalised".
If you can know in advance what complex, time-consuming queries a database will receive, you can precompute the results of those queries -- for example, replacing a 14-table join with a table that already contains the needed data.
That is different again. The two common reasons for that are:
- the database isn't Normalised in the first place, so queries on large tables are slow
- the proper cure is to Normalise properly
- your pretend "SQL" is so slow
- the proper cure for that is to obtain a genuine SQL Platform.
Such that you need to build an additional file (or Materialised View) to service the slow queries. Yes, that is de-Normalising, and on a grand scale, but it is worse, it is a 100% copy of those fields.